中國網/中國成長門戶網訊 數智驅動是當當代界科技浮現的新態勢和新特征。以ChatGPT模子為代表的GPT技巧的呈現,對學術、教導及財產界均帶來了變更。基本科研範疇的成長是年夜國科技競爭力的主要包管,直接決議了社會各方面提高的程序,主要性不問可知。今朝,在基本迷信研討範疇,基于GPT技巧的研討已發生較多衝破性結果,年夜說話模子技巧在幫助科研職員停止研發任務或懂得基本迷信題目的同時,也在轉變甚至推翻基本科研生態。是以,對于我國而言,公道地增進GPT技巧在科研中利用,不只意味著科研效力的晉陞,更意味著科研“彎道超車”機會的到來。
但是,也有另一部門學者在表達擔心和焦炙,以為GPT技巧固然可以在多個基本研討範疇極年夜地晉陞科研效力,但它需求被公道應用,而不克不及被濫用;更有學者以為將來GPT技巧甚至可以接收全部學術研討範疇。那么,GPT技巧在基本迷信研討範疇的利用近況若何?影響幾何?在研討中應用的鴻溝和隱患在哪里?針對這些題目,今朝學界尚未給出一個體系性的剖析框架和相干會商。為此,本研討安身以上題目,構建體系剖析框架,會商GPT技巧對于基本迷信研討的潛伏影響和能夠的應對方式,助力迷信研討生態的安康成長。
GPT技巧變更及在科研中的利用
ChatGPT在天然說話處置方面表示出來的機能已然到達了一騎盡塵的田地,要想進一個步驟懂得ChatGPT具有這般優勝機能的啟事,需求清楚GPT家族模子的成長途徑(圖1)。
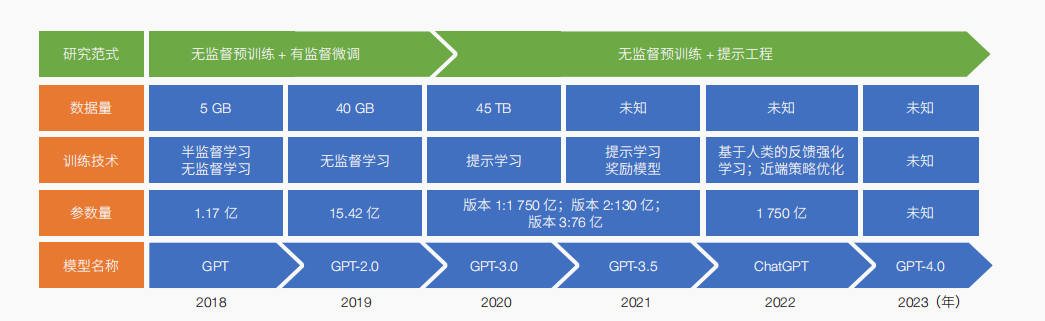
圖1 GPT技巧的成長過程
Figure 1 Development history of GPT technology
初代GPT模子采用無監視預練習與有監視微調相聯合的研討范式,側重練習一個無監視預練習說話模子,然后依據詳細的義務有監視地微調模子。GPT-2.0模子的研討范式同上,改良點為經由過程年夜幅晉陞練習數據量和模子範圍在有監視義務中完成了更好的後果。GPT-3.0模子采用無監視預練習與提醒工程相聯合的研討范式,即練習經過歷程中僅供給大批示例即可完成有監視義務。GPT-3.0模子共包括3個版本,分辨對應著分歧的參多少數字:1 750億、130億和76億。GPT-3.5為GPT-3.0的進級版,是一系列以GPT-3.0為基本的改良模子(包含code-davinci-002模子等),經由過程評價模子的問答表示和賞罰辦法停止優化更換新的資料而來。ChatGPT則是在GPT-3.5基本上引進了基于人類反應的強化進修(RLHF)和近端戰略優化算法(PPO)停止微調,應用偏好作為嘉獎電子訊號來微調模子,由今生成的回應版主合適人類的偏好。最后,GPT-4.0是在GPT-3.5版本的基本大將文字到多模態的連通釀成了實際。總而言之,GPT系列模子的勝利標志著人工智能(AI)從以公用小模子練習為主的“手任務坊時期”邁進到以通用年夜模子預練習為主的“產業化時期”,成為AI成長的分水嶺。
GPT技巧反動對基本迷信研討的影響
年夜說話模子的出色機能為基本迷信研討帶來了普遍的利用遠景,可以或許在浩繁迷信研討場景中利用或研發了一系列範疇年夜說話模子。文章將從利用牽引、道理驅動、立異主體遷徙3個視角剖析GPT技巧變更對基本科研的影響(圖2)。
利用牽引及其影響
包括GPT模子在內的年夜說話模子帶來了一系列的技巧反動,同時也在牽引著基本迷信範疇中迷信困難的衝破,成為加快科研過程,進步科研效力的助推器。
利用牽引的3個形式
依照由低到高的才能條理,可將GPT技巧在基本迷信研討中的利用分為3個形式(圖3)。
(1)工程化利用。該形式重要是增添GPT模子的對外接口,將其作為通用的科研數字助手,協助迷信研討的日常任務流程,晉陞學術效力。以中國迷信院研發的結果為例,GPT衍生模子的工程化利用案例如表1所示。
(2)學科科研立異的助力。該形式重要基于範疇數據庫微調出GPT衍生模子(如基于卵白質構造數據庫打造的Protein GPT),進步模子在特定迷信研討義務上的機能和適配性。今朝,ChatGPT的表示相似于通才,在細分的專門研究性上和行業中比擬頂級的專家還有很年夜的差距。將ChatGPT作為通用AI的技巧基座,經由過程在當地數據庫中停止微調,便可以晉陞模子在分歧範疇中的專門研究性,使其更實用于處理範疇場景題目,成為迷信假定空間的摸索者,今朝已有一些摸索性研討任務(表2)。此外,AI推進基本迷信研討的條件還在于AI技巧懂得分歧學科基本常識,晉陞多元常識的表現和融會。這種情形下,重要的艱苦是專門研究範疇迷信家與AI專家的彼此懂得水平低,彼此相互增進的妨礙依然較高。
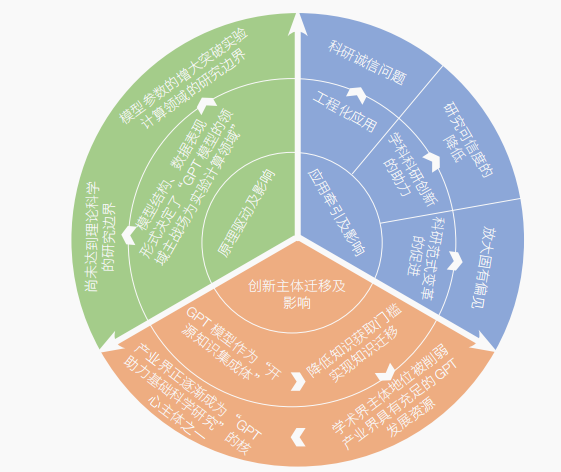
圖2 GPT技巧變更對基本迷信研討影響的全景圖
Figure 2 Panorama of impact of GPT technological change on fundamental scientific research
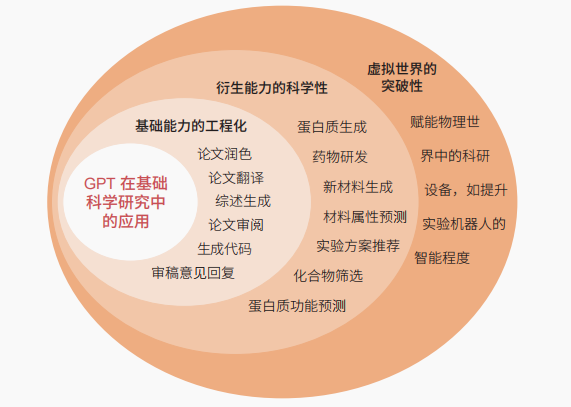
圖3 GPT助力迷信研討利用近況概念圖
Figure 3 Conceptual map of application status of GPT assists scientific research
科研范式變更的增進。今朝,“人機共生”的科研場景中,依據機械的智能水平由低到高將機械分為幫助做試驗的“試驗員”,幫助高維空間盤算的“AI科研助理”,自立停止科研全流程操縱、衝破人類迷信家認知瓶頸的“AI迷信家”,這3種情勢各有著重,并行成長。GPT技巧重要在后2種腳色中施展感化,即“科研范式變更增進”形式重要是盼望衝破“GPT類模子構建虛擬世界”的限制,經由過程加持試驗類的物文科研裝備,以“AI迷信家”的成分自立提出科研假說、自立design試驗計劃、自立驗證假說公道性(圖4)。
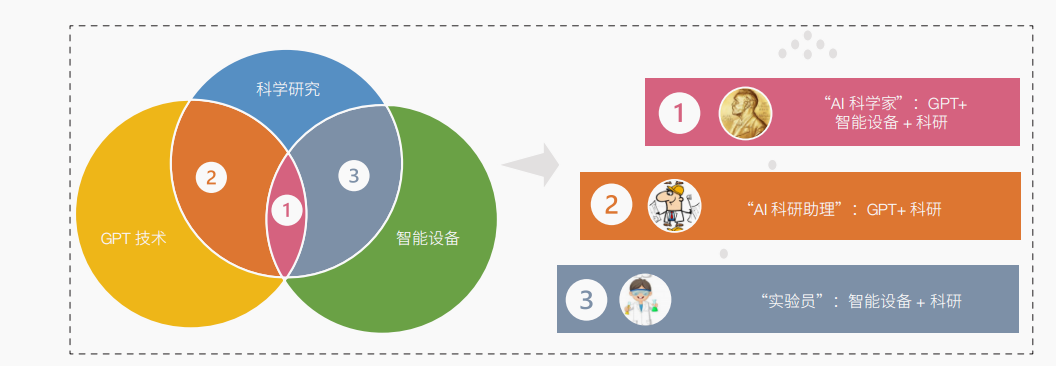
圖4 人機科研場景中的3種科研范式概念圖
Figure 4 Conceptual diagram of three paradigms in the human-machine scientific research scenes
表1 GPT衍生模子的工程化利用案例
Table 1 Engineering applications of GPT-derived models

今朝,GPT技巧與物理試驗裝備的銜接重要有2種方法:買通天然說話和機械指令之間的壁壘,主動天生機械人操縱指令。已有研討借助GPT-4模子依據天然說話的試驗指令主動天生一種試驗機械人操縱指令(OT-2),批示機械人主動停止生物學試驗,極年夜節儉了斟酌機械操縱細節編寫指令的時光;買通科研假定和迷信試驗之間的壁壘,自立天生試驗計劃。例如,中國迷信技巧年夜學研發的GPT衍生模子Chem-GPT,經由過程借助GPT模子“進修”50萬篇化學論文之后,主動給出其提出的化學試驗計劃,同時驅念頭器化學家“小來”做試驗,高效完成芬頓(Fenton)催化劑等化學品和新資料的研提問題。
利用形式的3個負影響
工程化利用形式中,不成防止空中臨科研誠信題目。從文本語法、格局的角度來看,ChatGPT是一個好的“論文制造者”。但是,一切的GPT框架產物都有一個配合特色,即制作者無法把握法式外部產生的變更,也就是我們常說的“黑盒”。由于模子參數過年夜,GPT年夜模子會不成控地發生大批的虛擬信息。此外,從科研倫理的角度來看,原創性是一篇論文的最基礎請求,用ChatGPT停止論文寫作,從情勢下去說與剽竊無異。更讓人擔心的是,跟著年夜說話模子的成長,編纂、出書商將很難辨別出AI代寫的文章。是以,如若對ChatGPT等AI技巧停止誤用和濫用,將對科研誠信發生不成控的沖擊。
表2 GPT衍生模子的迷信性利用
Table 2 Scientific applications of GPT-derived models

科研立異形式中,模子通明度的下降減弱了研討可托度。今朝,從GPT-4發布的技巧陳述來看,美國人工智能研討公司OpenAI出于競爭與平安等方面的斟酌,未公布模子範圍等技巧細節,且之后最前沿的研討也趨勢于不再發布相干論文開源技巧的細節。對研討者來說,模子技巧細節缺少通明度,不只是與開放迷信的趨向各走各路,也會違反迷信研討求證的科研立場。是以,假如持續應用GPT開源模子或官方供給的利用法式編程接口(API)進修範疇數據,則會要挾到成果可復現性,從最基礎上減弱研討的可托度;同時,無法從最基礎上答覆嚴重迷信研討題目的機理機制,進而無法有最基礎性衝破。
科研范式變更形式中,基于開源年夜數據練習的GPT技巧會潛伏地縮小固有成見。由于ChatGPT的練習數據起源于大批的internet數據,此中不成防止地記載了人類社會潛伏的輕視與價值抗衡。當ChatGPT輸入顯明具有成見的研討內在的事務時,不只影響研討者的判定,更能夠由於大批文本的普遍傳佈利用,加深研討者們的認知成見。此外,在馬斯克聯名幾千位盤算機迷信家的請愿公然信中,枚舉了8個AI風險猜測和掉敗形式,包含人類虛弱、認知腐蝕、詐騙等。
道理驅動及影響
基于GPT模子的迷信研討已獲得較多衝破性結果。例如ProGen模子與ESMFold模子等卵白質說話模子在卵白質構造猜測義務中表示凸起,成為GPT模子在迷信研討成長史中一座座里程碑。剖析以上成長近況背后的道理、特色及其將來的成長,對于科研職員厘清定位和科研鴻溝具有非常主要的啟示意義。
大批模子參數驅動試驗盤算題目的高維空間擬合
GPT類年夜模子焦點仍是Transformer的系統構造,之所以能在基本迷信研討範疇表示出色,實質仍是經由過程進修巨量的範疇迷信數據,借助大批模子參數對試驗盤算題目的高維空間停止了有用擬合。換言之,輸入的僅是統計學上的能夠性,缺少強無力實際常識的支持。
利用的主疆場為數據盤算密集型範疇的高維復雜迷信題目。剖析上述案例可以發明,GPT技巧在基本迷信研討中利用的主疆場為基本迷信研討中的試驗盤算範疇,即在分子生物學等數據積聚豐盛、構造化水平高、題目界說清楚的試驗盤算範疇。這重要是由於GPT技巧在基本迷信研討中利用的實質是GPT技巧的高維建模才能和迷信第一性道理的聯合。迷信盤算盼望做的是從第一性道理及試驗不雅測動身,將分歧標準實際世界產生的工作映射到盤算模仿的世界中。但是,跟著題目復雜度的晉陞,以往經典的盤算形式面對“維度災害”的題目。AI技巧則助力于處理迷信盤算中的維度災害題目,將分歧標準的物理模子有用銜接起來,而物理模子的歸納才能又能發生更大都據,從而推進更好的AI處理計劃。在此經過歷程中,模子參數是權衡模子復雜度和才能的主要目標,也是基本迷信研討高維數據盤算得以處理的主要原因。參數越多,意味著模子可以或許處置更多的數據,進修更多的範疇常識,更能輔助研討者摸索高維數據的內涵紀律和關系,繼而可以或許處理的迷信研討題目的復雜度也越高。例如,在生物學範疇,ProGen模子基于12億的模子參數進修卵白質中氨基酸排序的紀律,輔助研討者疾速從頭構建全新的卵白質。
模子適配性由數據表示情勢決議。由于GPT模子的練習、利用都是天然說話序列數據,是以,在包養網試驗盤算迷信題目中,只要與天然說話類似的序列範疇數據才可以用GPT模子停止編譯,進而進修包含此中的高維復雜常識。典範的範疇序列數佔有:範疇論文、專利數據是自然的天然說話數據。例如,Chem-GPT基于開源的GPT代碼,“瀏覽”近50萬的化學論文,可以基于進修到的論文常識主動答覆研討者提出的化學題目,甚至可以給出某化合物分解的試驗計劃,并高效完成化合物的研發。此外,還有基于4 000億字符練習的天生式專利說話模子——PatentGPT-J-6B,用于主動天生專利權力請求書。生物年夜分子,尤其是卵白質,可以當作是用遺傳password撰寫的語句,具有更為復雜的聯繫關係常識。以“生物版ChatGPT”的ProGen模子為例,經由過程進修氨基酸若何組分解2.8億個現有卵白質的“語法”,進修到了卵白質中氨基酸排序的紀律及其與卵白構造和效能的關系,進而可從頭開端天生跨多個家族和效能的天然全新卵白質。
道理驅動視角下的GPT模子利用鴻溝
(1)衝破試驗盤算範疇的研討鴻溝。當模子參數跨越臨界值,GPT模子將衝破試驗盤算範疇中的研討題目鴻溝,表示出必定的“涌現性”。AI年夜模子範疇的“涌現性”,淺顯性表述是在小範圍模子中不存在,但在模子參數跨越閾值的年夜範圍模子中存在的才能。這些才能在模子練習時沒有被特殊指定,而是由模子的多層構造和參數之間的彼此協同感化自覺發生的。依據Chung等學者的研討,模子參數範圍在年夜于62億的情形下,可涌現出之前較小模子不具有的包養才能,模子才能會完成從質變到量變的奔騰,浮現出驚人的迸發式增加。此外,年夜模子的涌現才能還存在一些懸而未決的題目,如是什么把持了哪些才能會涌現?若何把持模子涌現幻想的才能并確保不睬想的才能永不涌現?也有研討對年夜模子的“涌現力”提出質疑,以為只是報酬選擇懷抱目標的成果,當評價目標換成更為持續、光滑的懷抱目標之后,涌現景象就不那么顯明了,但今朝盡年夜大都研討支撐年夜模子涌現性的存在。總之,由于涌現景象的難以猜測性和不斷定性,需求謹嚴地處置涌現成果,并進一個步驟驗證和剖析其輸入成果。
尚未達到實際推導的研討鴻溝。固然GPT類模子在試驗盤算迷信題目上表示得很是傑出,甚至可以或許經由過程圖靈測試,但它尚不克不及自立停止實際推導的迷信研討義務。在“AI笛卡爾”模子的研討中,以為ChatGPT的年夜型說話模子邏輯才能無限,尚不克不及從正義化的常識和試驗數據中對天然景象模子停止道理性的推導。針對這個題目,重要從兩個角度剖析① 實際推導的焦點才能是需求懂得因果,而GPT模子表示出來的“智能”僅僅是源于數據擬合。AI迷信家朱迪亞•珀爾以為懂得起源于因果模子,而非源于數據擬合。ChatGPT僅僅依靠于大批文本數據停止預練習和微調,缺少對真正的世界的直接察看和經歷,難以判定事務的因果關系。它表示出來的“智能”僅僅是來自人類語料庫里已有的內在的事務,當題目在語料庫中不存在人類創作的謎底時,ChatGPT智能體系即是“無解”。但是,對于實際迷信來說,最主要的是推導出新的可以或許說明這個世界的實際公式。盡管AI年夜模子可以發生對的的“迷信”猜測(例如可以猜測小球活動軌跡的AI Physicist模子),但這種經過練習而來的AI體系,更像是一個逝世記硬背進修物理講義的先生,他了解每個題目的對的謎底,條件是這個題目在書里呈現過,但這并不是真正的迷信立異!朱迪亞•珀爾的研討提醒引進因果構造模子研討,經由過程2種研討退路的互補,構成效能—構造深度融會的智能體系或許是新的研討標的目的。 AI模子的黑箱任務機制招致GPT模子尚不具有實際的可說明才能。哲學家卡爾•波普爾指出,迷信家們追求的不是高度能夠的實際而是說明,即強盛而高度不成能的實際。但是,GPT模子依然是一種基于神經收集的黑箱模子,不克不及說明其外部的任務機制,其表示出來的“智能”也并非相似于人腦構造和認知機制,更像是一個形式婚配統計引擎,輸入的僅是統計學上的能夠性,這與實際情形下人類的思慮形式是年夜不雷同的。人腦只需求大批信息即可運作,由於它不追求揣度數據點之間的直接相干性,而是追求說明。也就是說,今朝的GPT模子焦點仍是描寫和猜測,輸入成果總仍是缺少了強無力的支持,不克不及像人腦一樣停止跨範疇、跨模態的實際推導。
立異主體遷徙及其影響
剖析上述內在的事務中的案例可以發明,財產界正逐步成為GPT助力基本迷信研討的焦點主體之一。究其緣由是GPT模子在迷信研討中的介入完成了常識包養網遷徙,同時下降了常識獲取門檻,由此減弱了學術界的主導位置;同時財產界憑仗其充分的AI技巧成長資本,使其成為GPT技巧立異窪地,進而無望成為基本迷信研討的焦點立異主體之一。
作為開源常識集成庫,GPT模子助力常識遷徙、下降常識獲取門檻
立異主體遷徙的最基礎緣由是大批數據練習過的神經收集變為一種新的數據、常識存儲模子,GPT類模子更是成為一個擁有豐盛常識與經歷的“專家”,一個開源常識集成庫,由此完成了分歧語種間的常識遷徙,同時下降了常識獲取的門檻。一方面,模子的練習語料是全球各語種的常識庫,年夜多以問答的情勢開源給模子的應用者,使全球任何語種的人都能應用年夜模子來進修分歧說話的常識,完成分歧說話間的常識遷徙;另一方面,由于GPT類模子成為一種新的數據、常識存儲模子,讓信息檢索方法從要害字檢索改變成具有完全語義的天然說話人機交互檢索,以智能問答的方法轉變了原有的常識查詢與獲取的方法,愈甚者是對科研方法的推翻。簡言之,GPT類年夜模子的存在將會下降迷信研討壁壘,吸引更多的先生、財產介入到迷信研討中來。
在年夜模子普及的時期,GPT年夜模子可以作為幫助講授和進修的東西,支撐各程度品級的先生停止特性化、自順應進修,并協助其介入到基本迷信研討中。例如,有研討測試了GPT-4在物理教導評價東西“力學概念測試FCI”中的表示情形,發明GPT-4以28分(滿分30分)的成就展現了其在物理學教導中的潛力。但是,GPT固然可以在通識與專門研究常識上供給極年夜輔助,但這取代不了立異性科研人才所必須的批評性思想、獵奇心、想象力、經過的事況與經歷,這些特質恰好是受過專門研究科研練習的人所特有的上風,也是人機協同科研場景中學者施展上風、尋覓定位的安身點。
迷信研討壁壘的下降,吸引了更多的企業和非學術機構介入到基本迷信研討中。例如,深圳晶泰科技通無限公司過練習卵白質類的Protein GPT模子,賦能試驗機械人的生物研發,使其研發重心逐步從“試驗機械人”轉向具有必定生物範疇常識的“試驗迷信家”。
充分的GPT技巧成長資本,助力財產界無望成為基本迷信研討的焦點立異主體之一
GPT模子作為開源常識集成庫的存在,下降了常識獲取、迷信研討的壁壘,必定水平上減弱了學術界在基本迷信研討中的主導和把持位置。而財產界憑仗其充分的AI技巧成長資本,即算力、數據、場景、人和本錢等上風的無機融會,使得人工智能驅動的迷信研討(AI for Science)正在向財產界傾斜。
從財產界對于AI技巧的人才、算力和資金等安排性資本投進上看,AI高科技企業資本已遠遠跨越學術研討機構。2020年,約70%的AI範疇博士進進財產界;2021年,財產界模子算力均勻比學術界模子年夜29倍;2021年,全球財產界破費了跨越3 400億美元用于AI,遠遠跨越了公共政策投資。而這種要害性資本的投進正轉化為日益凸起的AI研討結果中,如源于財產界的相干GPT模子結果有草創公司Profluent研發的ProGen模子。從GPT年夜模子擴大到全部AI研討範疇,財產界還研發,甚至是掌控著AI模子開闢東西(例如PyTorch和TensorFlow)、增進深度進修模子高效練習的硬件(例如張量處置單位TPU)和可公然拜訪的預練習模子(例如Open Pretrained Transformer模子)。也就是說,在數據密集型和盤算密集型的基本迷信範疇,如卵白質構造天生、化合物反映途徑天生、試驗計劃主動天生、高分子資料遴選等範疇,財產界對AI算法研討的安排也將付與財產界塑造基本研討標的目的的氣力。
該近況對于財產界和學界的學科研討定位也將發生相干影響。一方面,財產界貿易念頭的存在,促使他們將GPT等AI模子更多地利用到以利潤為導向的研討範疇,如醫藥、資料等試驗盤算範疇中的迷信題目場景中。即盤算密集型範疇迷信題目的衝破將漸漸由財產界和學術界配合衝破得來,相似于“巴斯德象限包養網”題目(巴氏殺菌的利用研討和基本研討之間存在相似的堆疊)。但是,這將潛伏領導社會成長標的目的,并對低支出程度國度的學術研討構成壁壘。另一方面,對于一些最基礎性的基本研討,如性命的來源、宇宙年夜爆炸、量子糾纏的構成機制等實際性研討題目,還需求高級院校與科研機構作為最重要的焦點立異主體。
關于我國基于GPT技巧成長基本迷信研討的提出
AI年夜模子經由過程重構人類常識檢索、應用的基礎方法,成為一種新的生孩子力。但是,由于GPT年夜模子具有重投進、長周期、快迭代、高風險等特色,決議了GPT年夜模子在基本迷信研討中的競爭是年夜國游戲。在這場比賽中,中國正處于急起直追的要害時代,亟待找到高東西的品質成長的新路。基于上述近況和影響,提出以下3方面提出。
投資研發國度自立可控、受常識產權維護的數據與盤算平臺,為GPT技巧推進基本迷信成長供給基本舉措措施扶植。縱不雅全球,有關促使“AI推進基本迷信研討”的政策調控陸續呈現。從GPT的完成要素看,重要從數據、平臺方面加年夜資本投進。 樹立高東西的品質迷信數據集勢在必行。年夜模子的“智商”取決于被練習的數據量和常識密度。據清楚,在GPT-3練習時語料清洗前為45 TB,清洗后570 GB,這表現ChatGPT模子練習時對數據清洗東西的品質具有極致的請求。但是,我國今朝高東西的品質的、自立可控的迷信數據庫較少。可行途徑之一為主動抽取已頒發科技結果中的迷信數據,構造化存儲在數據庫里,將其打形成AI for Science時期下主要的生孩子要素和計謀資產。將AI數據盤算平臺打形成科研經過歷程中的基本舉措措施,加年夜硬件和經費支撐。提出打造數據盤算通用平臺,嵌進科研經過歷程。通用的意義在于使開闢職員可以在此基本上處理更多有針對性的題目,疾速安排就任何學科範疇。此外,各地疏散式扶植智算中間,將全國同一的AI算力市場和辦事市場肢解為一個個孤立破裂的小市場,消解了我國年夜國年夜巿場的上風。只要依附年夜型科技公司或研發機構“煉年夜模子”,才幹慢慢補充中美在模子層面的差距。對于開源的AI算法停止財產化時,還需求留意到常識產權的風險。例如,深度神經收集算法的基本架構(如Transformer、Attention)已被谷歌請求專利,基于這些模子架構design的產物存在常識產權風險,或將障礙我國數智科研的財產化。是以,構建我國自立可控的平安的替換技巧尤為主要。
從產學研形式、青年人才資本和常識跨範疇活動3方面,為Al推進基本迷信成長營建可連續安康生態。鼎力倡導產學研形式,讓介入主體各顯本事,包管AI技巧安康成長導向。高校、科研機構擁有培育研發人才的義務和上風,更追蹤關心迷信道理;企業則擁有算力、資金戰爭臺扶植才能,對處理工程題目具有奇特上風,可以集中人力和財力停止攻關。將高校、科研機構開闢的上風與企業的產物化上風有用聯合,完成產學研各方的資本共享,上風互補,將安康推進我國基本迷信的成長。惹人育人,充足培育吸納國內外青年人才,包管人才資本的不竭供給。青年人才是AI技巧及基本迷信成長最為可貴的資本。ChatGPT團隊的平包養網排名均年紀僅32歲,憑仗對AI技巧的愛好和崇奉,便引爆全球新一輪AI技巧海潮。同時,該團隊中華人學者是一支主要的科技立異氣力。是以,激勵國外頂尖學者走出去、國際學者走出往,激起、培育青年人的科技愛好和崇奉,對增進國際前沿科技立異成長也具有主要意義。增進常識跨範疇活動,推進AI技巧與基本迷信成長無機聯合。為保證AI技巧賦能基本迷信研討的可連續性,我國可斟酌出臺相干跨範疇常識交通政策,激勵AI賦能下的基本迷信研討項目等辦法。例如,2023年3月27日,迷信技巧部會同國度天然迷信基金委啟動“人工智能驅動的迷信研討”專項安排任務,激勵盤算機、數據迷信、資料、化學、生物等學科的穿插融會,重構常識系統。
激勵人機協作與科研誠信監管并重,為Al推進基本迷信成長營建公然通明的周遭的狀況。以後,迷信研討不成防止地正進進人機協作的時期,微軟公司更是以為GPT-4是通用AI的火花。跟著相干GPT技巧產物在科研範疇睜開利用,相干東西能否會減弱研討職員的研討才能和位置成為重要題目之一。一方面,相似于Alpha Fold模子、RoseTTAFold模子如許“把一個公認的具有嚴重意義的迷信困難(卵白質構造天生)突進到簡直破解田地”的情形,展示了AI東西擁有經由過程圖靈測試、進而取得諾貝爾獎的潛力;另一方面,我們還需求甦醒地熟悉到以後的AI for Science模子,包含最新的GPT-4,存在著天生過錯文本信息、邏輯推理和因果揣度的表示才能較高等題目,是以它們尚不克不及算是一個完善的科研東西。總的來說,GPT類年夜模子的利用價值將在文本處置等方面輔助學者處置低級科研義務,或在高維數據建模方面輔助學者處置科研盤算義務,但其利用後果還取決于學者的認知程度。此外,針對“ChatGPT主動撰寫論文”的題目,國際外著名期刊年夜多持否決立場。Science明白表現制止將ChatGPT列為合著者,且不答應在論文中應用ChatGPT所生孩子的文本;Nature表現可以在論文中應用年夜型說話模子天生的文本,但不克不及將其列為論文合著者,只能在方式或稱謝中表白。但是,以ChatGPT為代表的通用型AI參與科研生涯已成定局,除了“保持人工驗證”“制訂問責規定”“投資真正開放的GPT模子”之外,還應加速構建公然通明的“AI文本探測器”,主動辨認AI天生的文本,從而使全部科研生態受害。。
(作者:孫蒙鴿、韓濤、王燕鵬、黃雨馨、劉細文,中國迷信院文獻諜報中間中國迷信院年夜學經濟與治理學院;編審:金婷,《中國迷信院院刊》供稿))